一、什么是DNS?
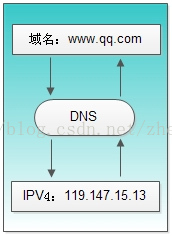
DNS( Domain Name System)是“域名系统”的英文缩写,是一种组织成域层次结构的计算机和网络服务命名系统,它用于TCP/IP网络,它所提供的服务是用来将主机名和域名转换为IP地址的工作。你可以把它想象成一本巨大的电话本。
举例来说,如果你要访问域名math.stackexchange.com,首先要通过DNS查出它的IP地址是151.101.129.69。
如果你不清楚为什么一定要查出IP地址,才能进行网络通信,建议先阅读我写的《互联网协议入门》。
DNS就是这样的一位“翻译官”,它的基本工作原理可用下图来表示:
二、DNS域名空间结构
域名系统作为一个层次结构和分布式数据库,包含各种类型的数据,包括主机名和域名。DNS数据库中的名称形成一个分层树状结构称为域命名空间。
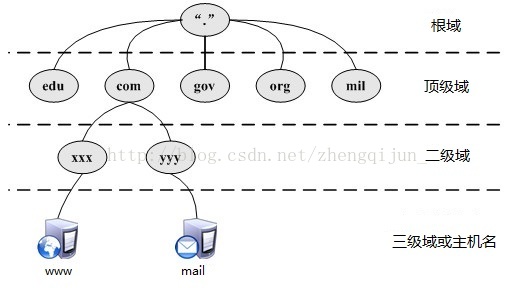
根域:DNS域名使用中规定由尾部句点'.'来指定名称位于根或者更高层次的域层次结构。
顶级域:用来指示某个国家、地区或者组织。采用三个字符,如com -> 商业公司,edu -> 教育机构,net -> 网络公司,gov -> 非军事政府机构等等。
二级域:个人或者组织在Internet使用的注册名称。采用两个字符,如:cn -> 代表中国,jp -> 日本,uk -> 英国,hk -> 香港等等。
主机:主机名处于域名空间结构中的最底层,主机名和域名结合构成FQDN,主机名是FQDN最左端的部分。
三、DNS的获取流程
DNS是应用层协议,事实上他是为其他应用层协议工作的,包括不限于HTTP和SMTP以及FTP,用于将用户提供的主机名解析为IP地址。
具体过程如下:
①用户主机上运行着DNS的客户端,就是我们的PC机或者手机客户端运行着DNS客户端了。
②浏览器将接收到的url中抽取出域名字段,就是访问的主机名,比如http://www.baidu.com/,并将这个主机名传送给DNS应用的客户端。
③DNS客户机端向DNS服务器端发送一份查询报文,报文中包含着要访问的主机名字段(中间包括一些列缓存查询以及分布式DNS集群的工作)。
④该DNS客户机最终会收到一份回答报文,其中包含有该主机名对应的IP地址。
⑤一旦该浏览器收到来自DNS的IP地址,就可以向该IP地址定位的HTTP服务器发起TCP连接。
四、DNS服务的体系架构
DNS服务的作用:把域名解析为IP地址,将IP地址解析为域名。
假设运行在用户主机上的某些应用程序(如Webl浏览器或者邮件阅读器)需要将主机名转换为IP地址。这些应用程序将调用DNS的客户机端,并指明需要被转换的主机名。(在很多基于UNIX的机器上,应用程序为了执行这种转换需要调用函数gethostbyname())。用户主机的DNS客户端接收到后,向网络中发送一个DNS查询报文。所有DNS请求和回答报文使用的UDP数据报经过端口53发送(至于为什么使用UDP,请参看为什么域名根服务器只能有13台呢? - 郭无心的回答)经过若干ms到若干s的延时后,用户主机上的DNS客户端接收到一个提供所希望映射的DNS回答报文。这个查询结果则被传递到调用DNS的应用程序。因此,从用户主机上调用应用程序的角度看,DNS是一个提供简单、直接的转换服务的黑盒子。但事实上,实现这个服务的黑盒子非常复杂,它由分布于全球的大量DNS服务器以及定义了DNS服务器与查询主机通信方式的应用层协议组成。
五、DNS为什么不采用单点的集中式的设计方式,而是使用分布式集群的工作方式?
DNS的一种简单的设计模式就是在因特网上只使用一个DNS服务器,该服务器包含所有的映射,在这种集中式的设计中,客户机直接将所有查询请求发往单一的DNS服务器,同时该DNS服务器直接对所有查询客户机做出响应。尽管这种设计方式非常诱人,但它不适用当前的互联网。因为当今的因特网有着数量巨大并且在持续增长的主机,这种集中式设计会有单点故障,通信容量(上亿台主机发送的查询DNS报文请求,包括但不限于所有的HTTP请求,电子邮件报文服务器,TCP长连接服务),远距离的时间延迟(澳大利亚到纽约的举例),维护开销大(因为所有的主机名-IP映射都要在一个服务站点更新)等问题。
DNS服务器一般分三种,根DNS服务器,顶级DNS服务器,权威DNS服务器。
六、DNS服务的工作过程
当 DNS 客户机需要查询程序中使用的名称时,它会查询本地DNS 服务器来解析该名称。客户机发送的每条查询消息都包括3条信息,以指定服务器应回答的问题。
● 指定的 DNS 域名,表示为完全合格的域名 (FQDN) 。
● 指定的查询类型,它可根据类型指定资源记录,或作为查询操作的专门类型。
● DNS域名的指定类别。
对于DNS 服务器,它始终应指定为 Internet 类别。例如,指定的名称可以是计算机的完全合格的域名,如im.qq.com,并且指定的查询类型用于通过该名称搜索地址资源记录。
DNS 查询以各种不同的方式进行解析。客户机有时也可通过使用从以前查询获得的缓存信息就地应答查询。DNS 服务器可使用其自身的资源记录信息缓存来应答查询,也可代表请求客户机来查询或联系其他 DNS 服务器,以完全解析该名称,并随后将应答返回至客户机。这个过程称为递归。
另外,客户机自己也可尝试联系其他的 DNS 服务器来解析名称。如果客户机这么做,它会使用基于服务器应答的独立和附加的查询,该过程称作迭代,即DNS服务器之间的交互查询就是迭代查询。
DNS的查询过程如下所示:
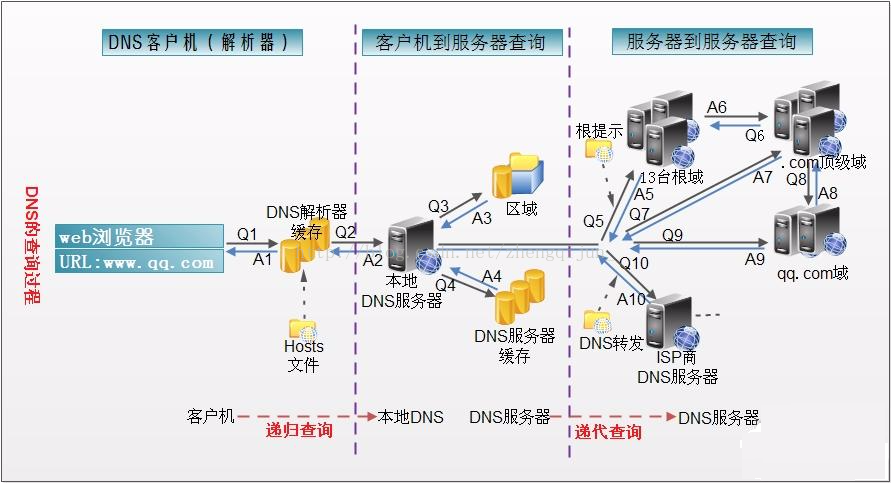
1、在浏览器中输入www . qq .com 域名,操作系统会先检查自己本地的hosts文件是否有这个网址映射关系,如果有,就先调用这个IP地址映射,完成域名解析。
2、如果hosts里没有这个域名的映射,则查找本地DNS解析器缓存,是否有这个网址映射关系,如果有,直接返回,完成域名解析。
3、如果hosts与本地DNS解析器缓存都没有相应的网址映射关系,首先会找TCP/ip参数中设置的首选DNS服务器,在此我们叫它本地DNS服务器,此服务器收到查询时,如果要查询的域名,包含在本地配置区域资源中,则返回解析结果给客户机,完成域名解析,此解析具有权威性。
4、如果要查询的域名,不由本地DNS服务器区域解析,但该服务器已缓存了此网址映射关系,则调用这个IP地址映射,完成域名解析,此解析不具有权威性。
5、如果本地DNS服务器本地区域文件与缓存解析都失效,则根据本地DNS服务器的设置(是否设置转发器)进行查询,如果未用转发模式,本地DNS就把请求发至13台根DNS,根DNS服务器收到请求后会判断这个域名(.com)是谁来授权管理,并会返回一个负责该顶级域名服务器的一个IP。本地DNS服务器收到IP信息后,将会联系负责.com域的这台服务器。这台负责.com域的服务器收到请求后,如果自己无法解析,它就会找一个管理.com域的下一级DNS服务器地址(http://qq.com)给本地DNS服务器。当本地DNS服务器收到这个地址后,就会找http://qq.com域服务器,重复上面的动作,进行查询,直至找到www
. qq .com主机。
6、如果用的是转发模式,此DNS服务器就会把请求转发至上一级DNS服务器,由上一级服务器进行解析,上一级服务器如果不能解析,或找根DNS或把转请求转至上上级,以此循环。不管是本地DNS服务器用是是转发,还是根提示,最后都是把结果返回给本地DNS服务器,由此DNS服务器再返回给客户机。
从客户端到本地DNS服务器是属于递归查询,而DNS服务器之间就是的交互查询就是迭代查询。




